name-alert
Using TinyML and Ardunio to alert when your name is called on a conference call
Project Summary
If you’ve been working from home during the COVID-19 pandemic, I’m sure you’ve experienced “Zoom Fatigue”. I was joking with a few friends recently that so many people zone out or multi-task during long zoom calls, and then don’t hear and/or panic when their name is called. I joked that I could build an AI device that could listen for your name to be spoken and then alert you.
In a few hours I got this working!
In my reading about TinyML, I came across Edge Impulse which has incredible software that allows even beginners to create embedded AI models. Edge Impulse offers an almost no-code platform (you’ll need to be comfortable working with a command line, and knowledge of C++ is helpful to work with the Arduino interface) to collecting data, building/validating a model, and deploying the model to a microcontroller. I loosely followed this tutorial from Edge Impulse.
Obvious disclaimer for my employer: This was just a project for a laugh that I have no intention of actually using in real life, and I did not use any real meetings for training or validation.
What is TinyML/Embedded AI and why did I use it?
There are some simple ways you could do this by streaming the data to the internet, like Google’s Speech-to-Text API, but this is not a secure solution since all of your meeting content would be sent to remote servers and while I’m not questioning Google’s security here, there are obvious privacy concerns.
With recent advances AI libraries designed for small edge devices like TensorFlow Lite, it is possible to build and deploy an AI/ML model “at the edge” on a small microcontroller wihtout network connectivity. If the device can listen to speech and make classifications remotely with no onboard storage or network connectivity, then we can be assured that there are no privacy or security concerns about having a device listen in on our communications. I bought an Arduino Nano BLE Sense a few months back to learn more about embedded AI in microcontrollers, but hadn’t found a great use case besides having some fun with the built-in accelerometer. The Nano BLE Sense only has 1MB of storage and no network connectivity, so we can be assured that there is no hidden way it is storing audio or streaming to the internet (note: it does have bluetooth low energy capability but I am not using it here and let’s ignore for now since this project is just for fun).
Model Building and Deployment
1. Collect Data
To build a model which will recognize my name, I needed two classes of data (in this case, audio clips): someone saying the word Brandon, and literally any other type of noise. To collect samples of the word “Brandon”, I kept recording audio clips of me saying my name in different tones. I got my wife to record a few as well, but to build a better model I’d ideally want recordings as many different people as possible.
To collect data which is “not Brandon”, ideally I’d want to record a bunch of meeting audio when people aren’t saying Brandon. Obviously I wasn’t going to use real meetings, but thankfully there are plenty of existing audio datasets out there for building ML models. I considered for a second just recording a bunch of audio from The Office, but I ended up using background noise from the The Microsoft Scalable Noisy Speech Dataset (MS-SNSD).
I then had to turn the raw audio into a simplified format which the model can understand. I will admit I have no experience in audio processing, but relying on the advice from Edge Impulse I used their MFCC processing functionality.
2. Train and Test Model
There are any number of types of classifiers I could use here, but from previous reading on audio processing I wanted to try a neural network. Edge Impulse uses the Keras library, which I’ve used directly in python before, but the GUI makes it really simple to create a model if you don’t have prior experiene with Python. For this short post I won’t go too in-depth with a discussion of the model since my goal was just a fun proof of concept, not an in-depth exploration of using neural networks for audio classification.
I didn’t spend too much time perfecting the model, but a simple neural network with two 1D Conv layers yielded pretty great results right out of the box (with 20% held for test data):
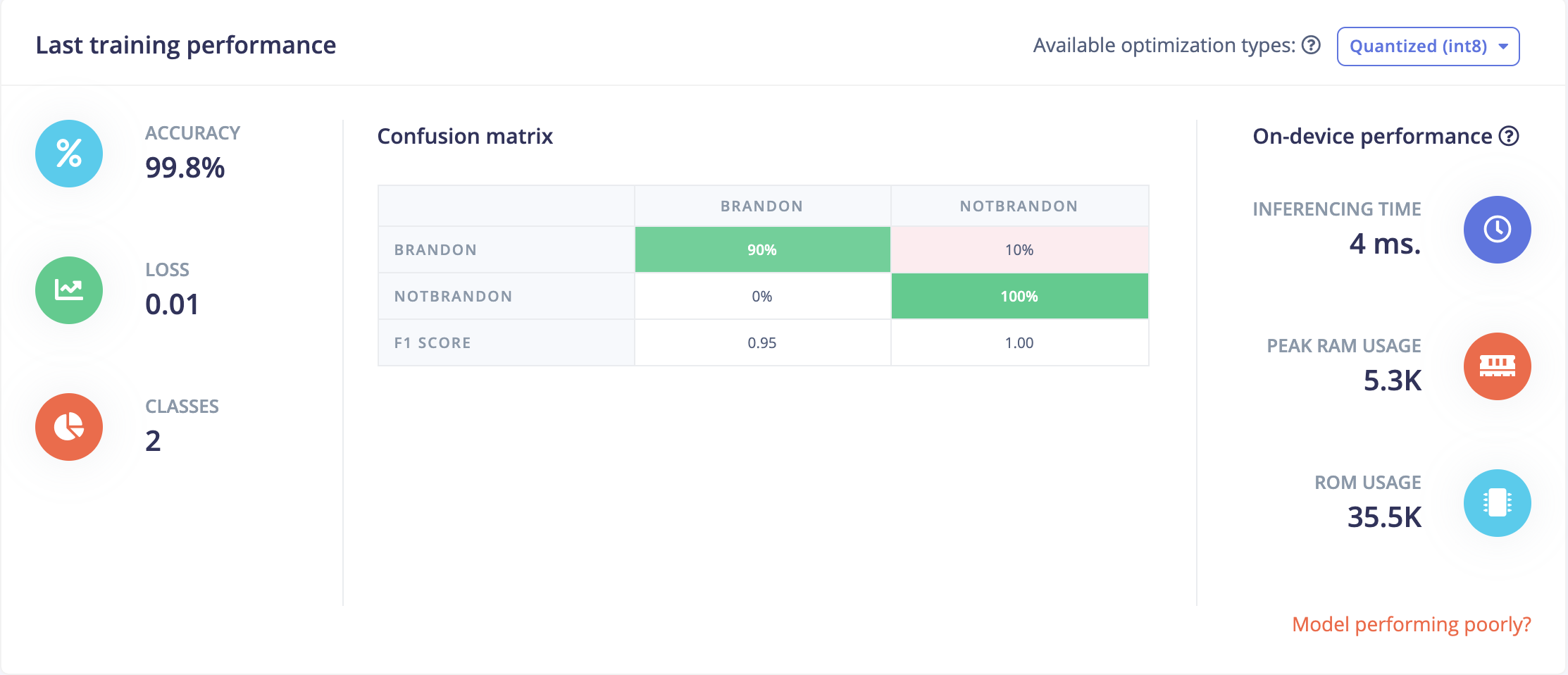
In theory I would have spent much more time testing and perfecting this model, but again, I was much more focused on the Arduino aspect of the project than the model building.
3. Deploy Model
We need to turn the model into a format which can run on the Arduino, which would either be compiled binary or Arduino code (essentially, C++). Both Edge Impulse and TensorFlow Lite have several options for this step. I exported my model from Edge Impulse directly to Arduino code which I then modified to tinker with a simple LED circuit. Edge Impulse created the C++ and header files needed to run the classifier, so I just needed to write some simple logic to flash an LED when the model detected that “Brandon” was heard. I made any changes to the code in the file src/recognize_brandon.cpp in the repo. Everything else, including the bulk of that file was generated by Edge Impulse!
In the loop() function on the Arduino, the audio sensor is constantly running samples through the model and calculating the “probability” that the word “Brandon” has been heard. If this happens, a function will be triggered to output a pulse out of a given pin to flash an LED for 1 second. I flashed my recognize_brandon program to the Arduino board, disconnected from USB and ran on AAA batteries (to prove that the model wasn’t interacting with my laptop or the internet through USB).
I wired pin 13 on the Arduino board to flash an LED with a 220Ω resistor:

Check out another video of the device in action:
Further work
As I said, this was only just for fun and to create a basic example. A proper implementation of this concept would require considerably more training data and model tuning. Of course, simply flashing a light when your name is called might not even be that useful, since by the time your name is called, it’s already too late if you’re not paying attention! Maybe what I actually need to build is a model that can predict when your name will come up…
Interested in learning more?
Get in touch over email at brandon.f.cohen@gmail.com. Check out some of my other projects at https://www.brandonfcohen.com.